虽然白宫嚷嚷着要淘汰C和C++这类“内存不安全”语言,全部换成Rust,但是想想它的主人都可以是Trump这种技术上毛都不懂的白痴,所以也就听听罢了。不过我们总归是要关注内存安全的,为了有效检测内存破坏类的bug,开发人员引入了memory safety sanitizer这种神奇魔法,如果你还不知道什么是memory safety sanitizer,可以试试去问AI,我们的测试表明AI回答得并不好(误),建议你去看看Trail of Bits Blog的一篇文章:
https://blog.trailofbits.com/2024/05/16/understanding-addresssanitizer-better-memory-safety-for-your-code/
总之,今天并不是科普memory safety sanitizer,而是要介绍一篇来自IEEE S&P 2025的论文Evaluating the Effectiveness of Memory Safety Sanitizers,这篇论文的作者开发了一个叫做MEST的sanitizer评估工具,对不同sanitizers的检测能力从多个维度进行了横向比较,我们最喜欢这种评测类文章了对不对?不看细节只看结果也很爽~

打住打住,我们肯定不是那种只看结果的公众号。要详细了解本文,你需要先去了解两篇比较重要的前驱论文,第一篇论文是2013 IEEE S&P上的经典SoK论文Eternal War in Memory,它把内存安全漏洞大致分为了temporal error和spatial error两种,还给了一幅经典的attack model图:
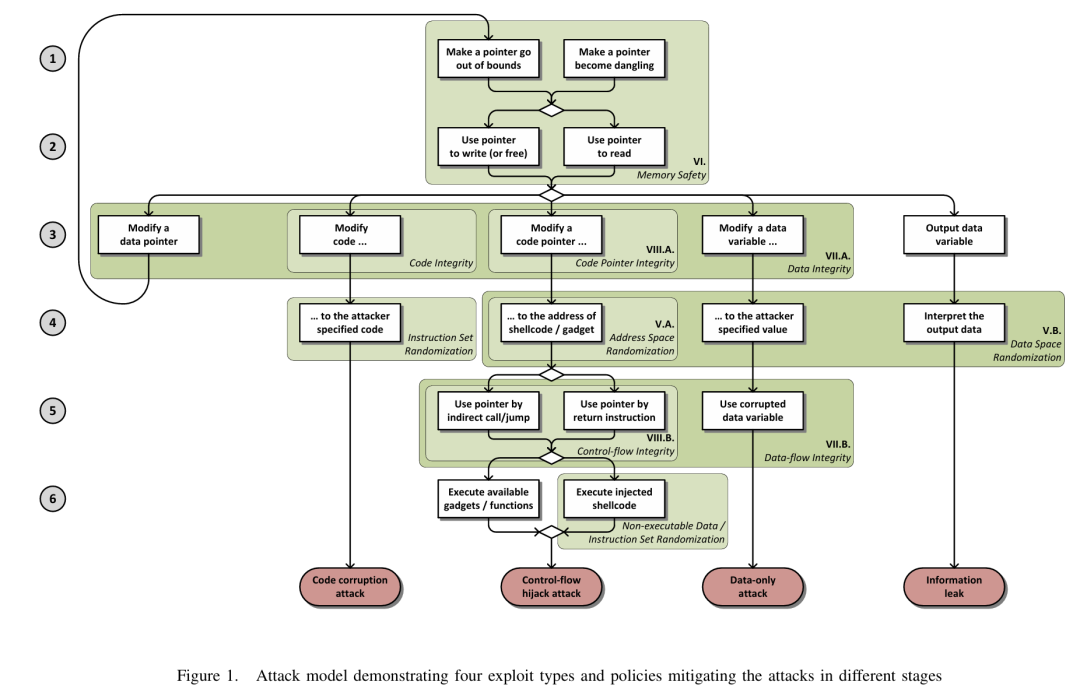
第二篇论文也是来自IEEE S&P的SoK论文,发表于2019年,标题叫做Sanitizing for Security,一看就知道是对memory safety sanitizer的分类总结。作者讨论了45个不同的memory safety sanitizer,有兴趣的同学可以去考古:
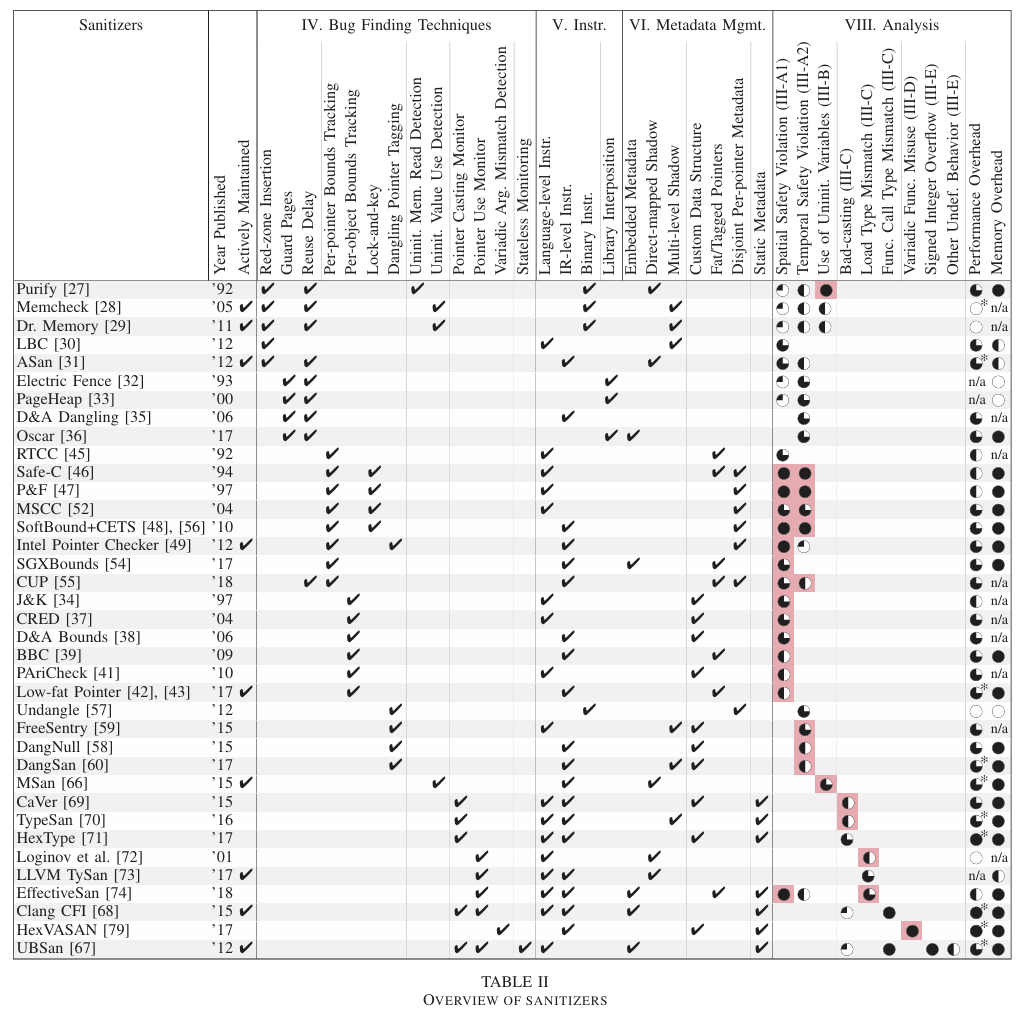
回到我们今天推荐的论文,作者基于上面两篇论文的成果,对45种在Sanitizing for Security讨论过的sanitizers和18个新出现的sanitizers进行了系统性评估,主要关注它们对temporal error和spatial error两种内存安全问题的检测能力(不考虑其他类型错误,比如未初始化或者条件竞争)。作者调查的sanitizer(如下表)最早可以追溯到1992年(那是一个春天),最新的则是2024年的研究工作,横跨2的5次方年!
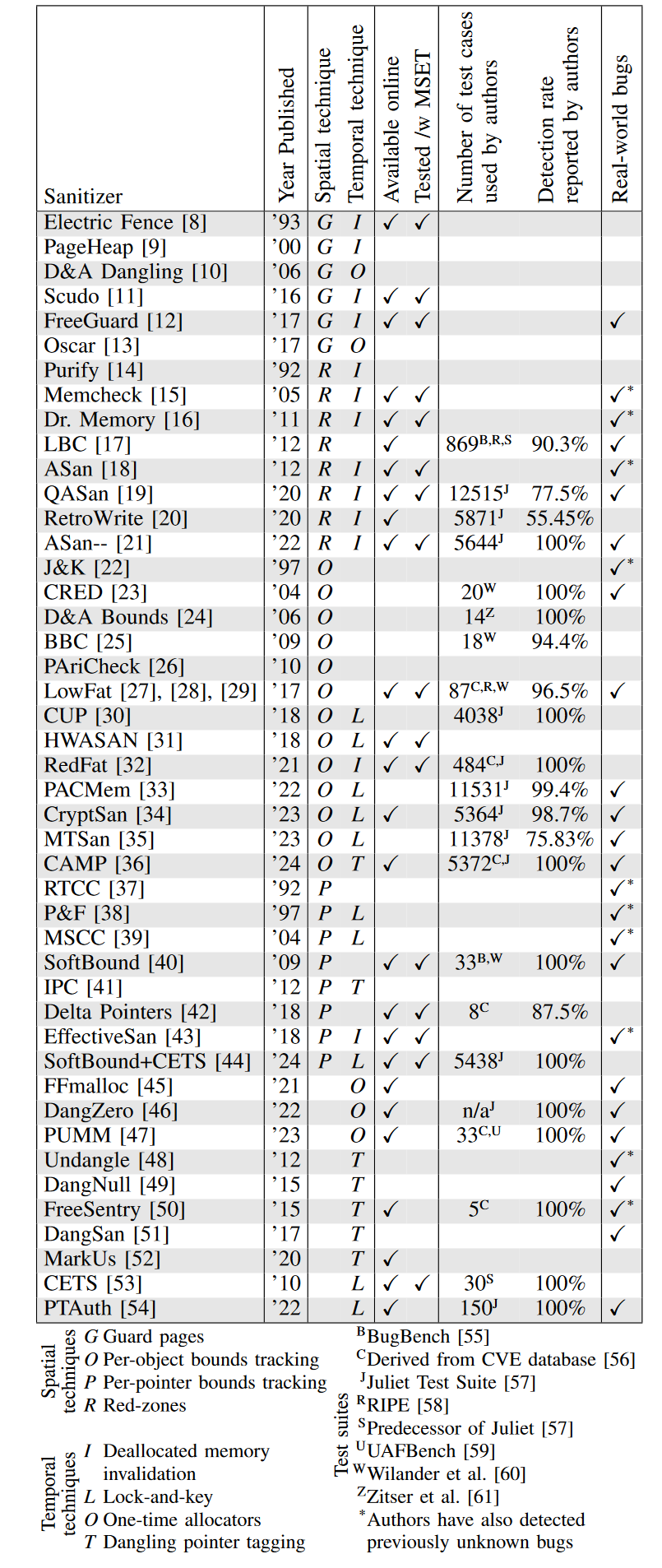
好,接下去我们要讲一些技术细节,会有点枯燥,这种枯燥我们把它归咎于技术本身的难度以及今天的责任编辑 L0tus~
首先是要讲一下sanitizer对spatial error和temporal error是怎么检测的,针对spatial memory bugs,有两种类型的检测技术——location based和identity based finding techniques,这两种检测技术有什么区别呢?
Location based检测技术主要采用诸如guard page和red zone这样的方式来报告漏洞。在使用guard page技术的sanitizers例子里,除了2019年的Sok论文中提到的一系列sanitizers以外,作者还特别介绍了Scudo和FreeGuard这两种sanitizer。这两种sanitizer都避免在每个对象之间彻底放置guard page。相反,FreeGuard选择在整个堆中随机分布保护页,而Scudo是一种强化的分配器而不太像经典的sanitizer,它仅将保护页放置在大对象和仅包含相同大小的小对象的专用内存区域之间。Red zone则是指那些标记为不可访问,并放置在对象之间的小块内存。Asan是采用这种技术的最知名的sanitizer,近几年也没有特别新鲜的采用red zone的新工具。
Identity based检测技术是通过维护spatial memory或自定义元数据结构中每个对象的边界来跟踪对象身份。它使得sanitizers能够从概念上检测所有类型的空间内存错误,包括对象内错误。本文的参考文献22-30都是关于Per-object bounds tracking sanitizer的,它们使用各种技术来维护对象元数据并将指针链接到其预期指示对象的元数据。

接下来是对temporal memory bug的检测,思想很简单,给内存对象做好标记,只要内存对象已被释放,而指向该对象的指针还被使用(use-after-free或者double free),那么就报告。在2019年的SoK论文中已经介绍了三类技术:reuse delay、dangling pointer tagging和lock-and-key,本文则把所有的sanitizer分为了Object Invalidating Sanitizer和Pointer Invalidating Sanitizer两种大类。
讲完了背景,论文进入到核心部分——对sanitizer的评估,作者首先抛出了一个新的内存错误分类法,号称该分类法的优势是能够突出sanitizers之间的差异,从下面两幅图来看确实非常浮夸:
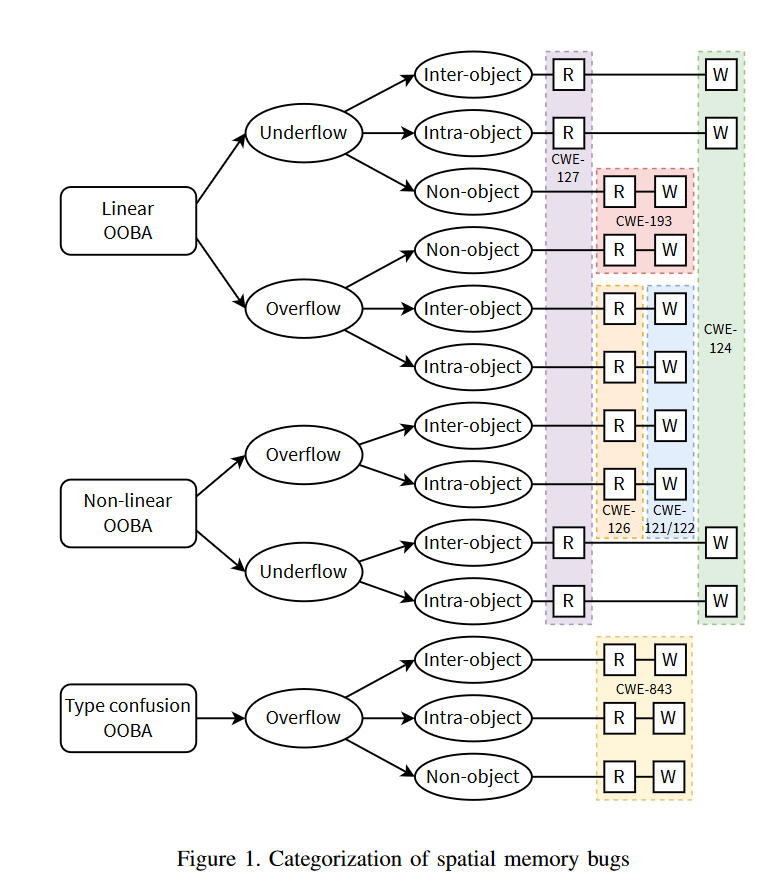
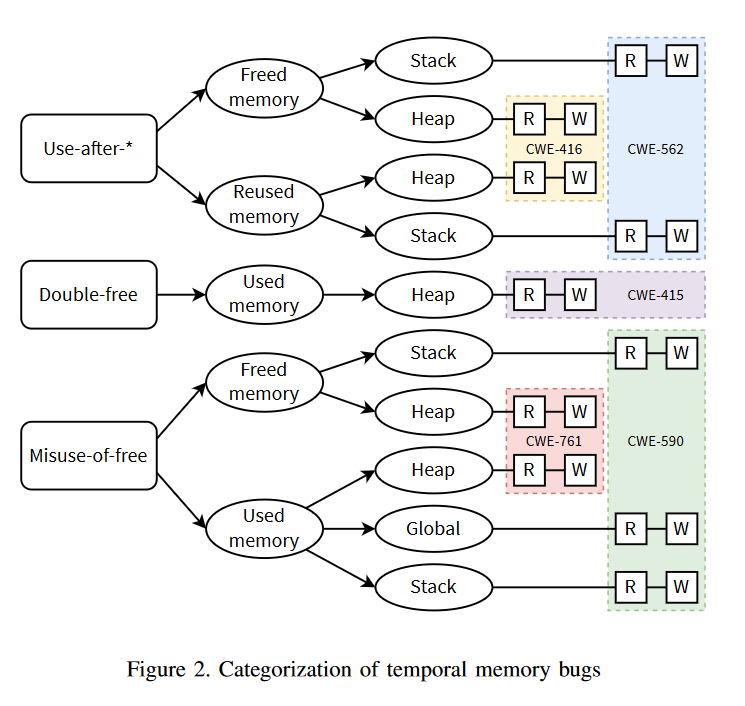
为了把这个巨复杂的内存错误分类法转化为评估工具,作者将内存错误解构为三个基本属性:易受攻击的对象所在的内存区域、导致内存损坏的错误类型以及对该对象的访问类型。对于每个属性定义了不同的原语,从中可以形成实际的内存损坏以及后来的测试用例。下图描绘出了这些原语形成实际内存破坏的可能组合。

作者接下来介绍了他们的MSET(也就是Memory Sanitizer Evaluation Tool的缩写),当然也是内存不安全的(用C++开发)。MSET工具结合了内存区域、错误类型和访问类型原语,创建了一大堆很小的C程序(片段)作为测试用例(为什么要搞这么小的测试用例,可能是为了确保被测试的sanitizer都能编译?),然后用每个sanitizer编译这些测试用例,按顺序执行它们,根据其退出状态评估sanitizer的能力。下面给出了一些生成测试用例的模板:


对于每个测试用例,MSET还会生成一个无错误版本,旨在检测sanitizers的误报。MSET在验证测试的sanitizer时候,首先要看它是否能编译和运行测试用例(而不是先关心内存错误),同时是否能够成功执行原始测试用例的功能。只有当功能性指标得到满足后,实际的(有bug的)测试用例才会被编译并执行。此外,MSET还引入了一系列的test case变异策略,这部分细节大家可以去论文的4.2章看看,主要目的是要确保sanitizer对于同一个内存bug的不同变种(实际上还是同一个问题,但是触发bug的细节有点差异)都能检测出,如果做不到这一点,作者认为sanitizer也是有问题的。
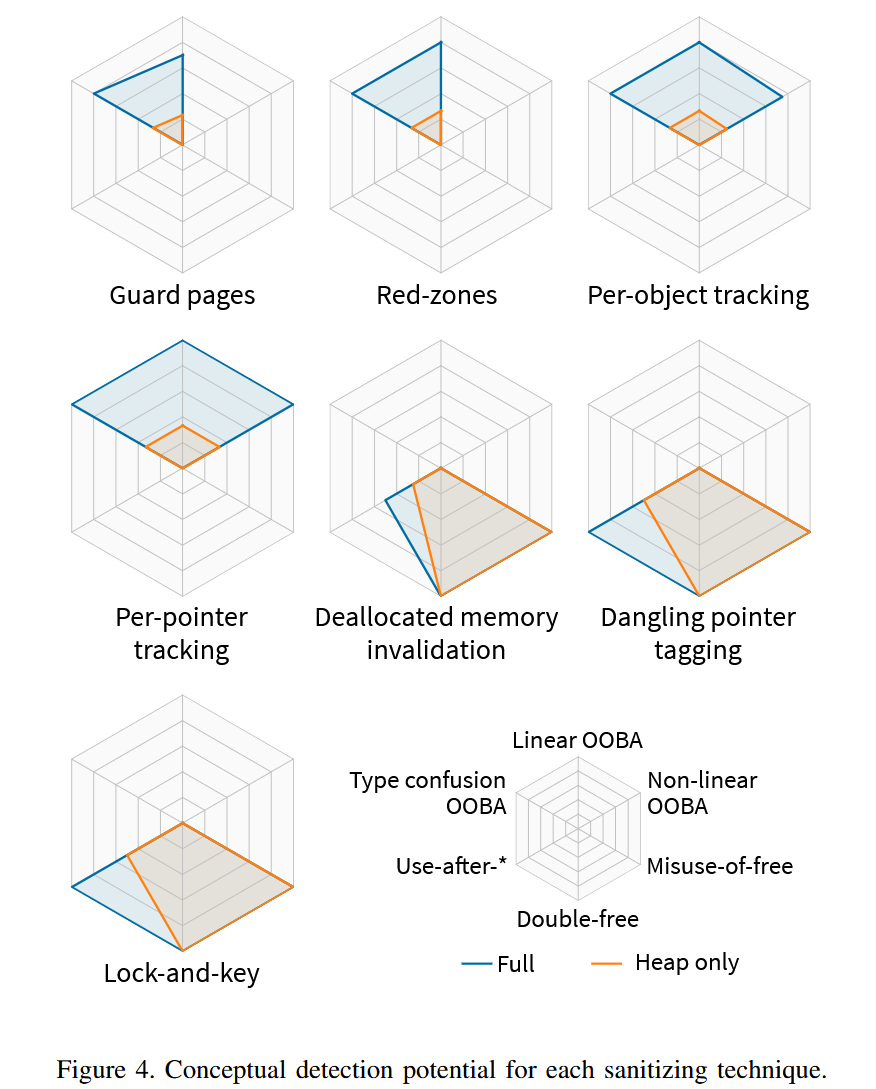
最后,作者说他们只测试了16种sanitizer(前面说好的45+18,瞬间淘汰了一大半,大概很多都运行不起来了)。接下来,作者把sanitizer的上限做个界定,就是根据sanitizer所使用的技术,把每个技术在对六类不同的内存错误(三种不同的temporal error,主要都是out-of-bounds access也就是OOBA,三种不同的spatial error,分别是use-after-*、double free和misuse-of-free错误)的检测能力上限给标记出来了(下图,采用6维雷达图,每个轴代表的是针对相应错误类型成功缓解的测试用例的百分比,本质上是错误检测率):
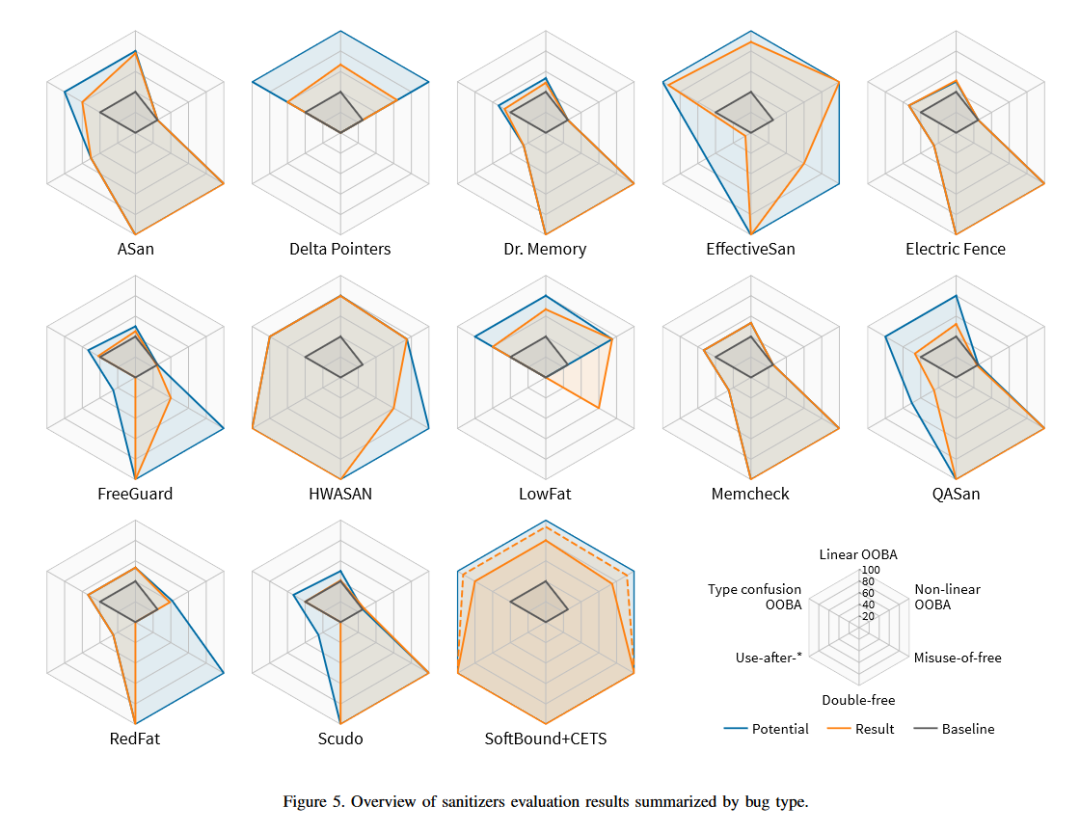
看到这里,你终于可以看到想要的结果了(是不是在心里面咒骂责任编辑,早点放下面的图就完事了),到底是谁最强sanitizer?似乎是SoftBound+CETS这个组合(都是同一组作者),不过这两个工作是2009年PLDI论文和2010 PLDI workshop论文提及的,都有点古老,难道学术界这几年还(学习Intel)开倒车了?大家怎么看,欢迎在评论区留言!
论文:https://publica-rest.fraunhofer.de/server/api/core/bitstreams/4400cfa7-fa25-4ac5-b95e-0c4485c88f99/content